
在近日备受瞩目的全球闪存峰会(Flash Memory Summit)上,一家名为NEO Semiconductor的创新公司投下了一颗重磅炸弹,其首席执行官Andy Hsu发表主题演讲,正式公布了其革命性的下一代高带宽内存技术——X-HBM。该技术宣称将带来颠覆性的性能飞跃:与当今主流的传统HBM(高带宽内存)相比,X-HBM架构能够提供高达16倍的内存带宽和10倍的存储密度,直指当前人工智能(AI)和高性能计算(HPC)领域面临的最大痛点——“内存墙”问题。
传统HBM的瓶颈与X-HBM的破局之道
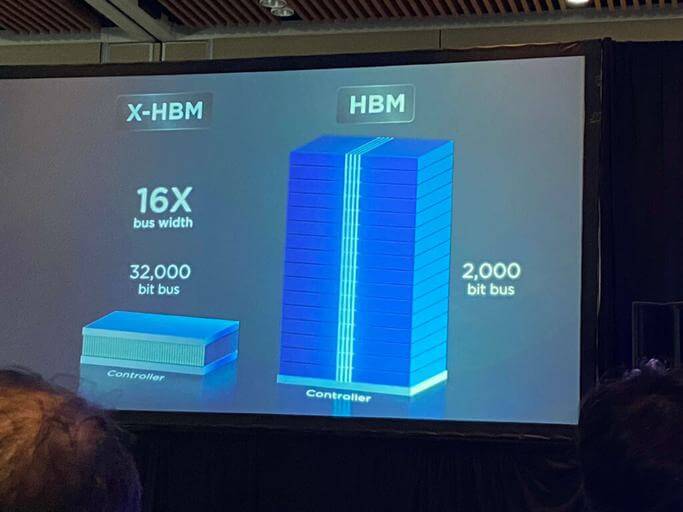
随着AI大模型的参数量和计算需求呈指数级增长,GPU等计算核心的处理能力飞速提升,但数据传输的速度却逐渐成为系统整体性能的瓶颈。传统HBM技术通过硅通孔(TSV)技术将多个DRAM裸片(die)垂直堆叠,并通过一个1024位(bit)的宽数据总线与处理器连接,极大地提升了内存带宽。然而,这种架构在进一步扩展时面临着物理和成本上的巨大挑战。增加数据总线宽度和堆叠层数变得越来越困难且昂贵,使得带宽和密度的增长速度难以跟上算力的发展步伐。
NEO Semiconductor提出的X-HBM架构则另辟蹊径,彻底改变了游戏规则。其核心创新在于采用了一种3D交叉点(3D cross-point)架构,这与传统HBM基于TSV的垂直堆叠方式截然不同。通过这种全新的设计,X-HBM实现了惊人的32K位(32768位)超宽数据总线,是传统HBM 1024位总线的32倍。这种总线宽度的几何级数增长,正是其实现16倍带宽提升的根本原因。同时,该架构还允许在每个裸片上实现高达512 Gbit的潜在存储密度,这为在更小的物理空间内集成海量内存提供了可能,从而实现了10倍的密度提升。
性能飞跃:数字背后的巨大意义
为了更直观地理解X-HBM带来的变革,我们可以将其关键性能指标进行分解:
带宽提升16倍:这意味着处理器与内存之间的数据交换速度将发生质的飞跃。对于训练万亿参数级别的AI模型而言,更快的带宽可以显著缩短数据加载时间,让昂贵的计算核心减少等待,从而大幅提升训练效率,降低训练成本。在科学计算、气候模拟等HPC应用中,这也意味着可以处理更复杂、更庞大的数据集,解锁前所未有的研究能力。
存储密度提升10倍:更高的密度意味着可以在单个芯片封装内容纳更多的内存容量。这将使得服务器和数据中心能够在不增加物理空间占用的情况下,大幅提升内存容量,从而降低数据中心的总体拥有成本(TCO)和能耗。对于边缘计算设备而言,这也意味着可以在紧凑的空间内集成更强大的处理能力。
32K位超宽数据总线:这是X-HBM技术皇冠上的明珠。它打破了传统内存接口的束缚,实现了前所未有的并行数据传输能力,从根本上解决了内存访问的拥堵问题。这种设计理念的转变,可能将引领未来内存架构的发展方向。
市场影响与未来展望
NEO Semiconductor的X-HBM技术目前仍处于架构发布阶段,从概念走向大规模商业化生产,还需要与主要的内存制造商(如三星、SK海力士、美光)和芯片代工厂进行深度合作。然而,这一技术的公布本身就已经对半导体行业产生了巨大的冲击波。它为业界展示了一条摆脱现有HBM技术演进困境的全新路径。
如果X-HBM能够成功实现其宣称的性能目标并商业化落地,它将不仅巩固NEO Semiconductor在内存技术领域的创新者地位,更有可能重塑整个高性能计算和AI芯片的市场格局。NVIDIA、AMD、Intel等芯片巨头将获得一个强大的新武器来构建其下一代数据中心加速器。对于整个科技生态而言,一个不再受限于内存瓶颈的计算未来,将催生出更加强大、更加智能的AI应用,推动科学研究和社会发展的边界不断向外拓展。Andy Hsu在演讲中强调,X-HBM的设计初衷就是为了“喂饱”未来最强大的AI处理器,而这次发布,正是迈向这一目标的关键一步。